

Sweating the Details - Rethinking Google Keyword Tool Volume
[Estimated read time: 13 minutes]
I joined Moz in August of 2015 and fell right into the middle of something great. Rand had brought his broad vision of a refined yet comprehensive SEO keyword tool to a talented team of developers, designers, data scientists and project managers... and now, me.
I was hoping to ease in with a project that was right up my wheelhouse, so when the "Volume" metric in Keyword Explorer was pitched as something I could work on, I jumped right on it. In my mind, I was done the second the work was offered to me. I already had a giant keyword volume database at my disposal and a crawling platform ready to fire up. All I had to do was tie some strings together and, voilà.
Peer pressure
It was subtle at first, and never direct, but I quickly began to see something different about the way Moz looked at problems. I've always been a bit of a lazy pragmatist — when I need a hammer, I look around for something hard. It's a useful skill set for quick approximations, but when you have months set aside to do something right, it's a bit of a liability instead.
Moz wasn't looking for something to use instead of a hammer; they were looking for the perfect hammer. They were scrutinizing metrics, buttons, work flows... I remember one particularly surreal discussion around mapping keyboard shortcuts within the web app to mimic those in Excel. So, when on my first attempt I turned up in a planning meeting with what was, essentially, a clone of Google Keyword Planner volume, I should have seen it coming. They were polite, but I could feel it — this wasn't better, and Moz demanded better in their tools. Sometimes peer pressure is a good thing.
If it ain't broke, don't fix it.
Rand was, unsurprisingly, the first to question whether or not volume data was accurate. My response had always been that of the lazy pragmatist: "It's the best we got." Others then chimed in with equally valid questions — how would users group by this data? How much do we have? Why give customers something they can already get for free?
Tail tucked between my knees, I decided it was time to sweat the details, starting with the question: "What's broke?" This was the impetus behind the research which lead to this post on Keyword Planner's dirty secrets, outlining the numerous problems with Google Keyword Planner data. I'll spare you the details here, but if you want some context behind why Rand was right and why we did need to throw a wrench into the conventional thinking on keyword volume metrics, take a look at that post.
Here was just one of the concerns — that Google Adwords search volume puts keywords into volume buckets without telling you the ranges.

Well, it's broke. Time to sweat the details!
Once it became clear to me that I couldn't just regurgitate Google's numbers anymore and pretend they were the canonical truth of the matter, it was time to start asking the fundamental questions we want answered through a volume metric. In deliberation with the many folks working on Keyword Explorer, we uncovered four distinct characteristics of a good volume metric.
- Specificity: The core of a good volume metric is being specific to the actual average search volume. You want the volume number to be as close as possible to reality.

- Coverage: Volume varies from month to month, so not only do you want it to be specific to the average across all months, you want it to be specific to each individual month. A good volume metric will give you reasonable expectations every month of the year — not just the whole year divided by 12.

- Fresh: A good volume metric will take into account trends and adjust to statistically significant variations which diverge from the previous 12 months.
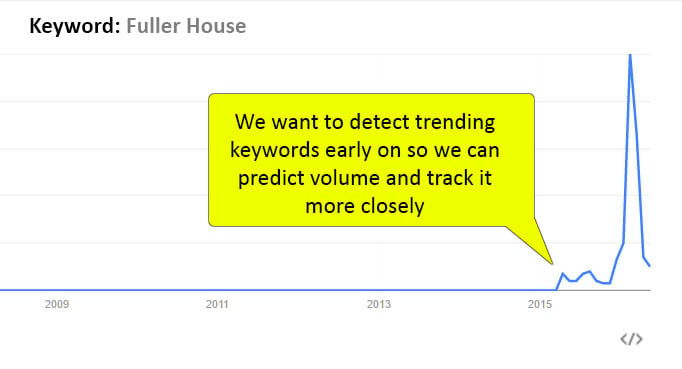
- Relatable: A good volume metric should allow you to relate keywords to one another when they are similar in volume (i.e.: grouping).



We can actually apply these four points to Google Keyword Planner and see its weaknesses...
- Specificity: Google's Keyword Volume is a yearly rounded, bucketed average of monthly rounded, bucketed averages
- Coverage: For most keywords, the average monthly search is accurate only 33% of the months of the year. Most months, the actual volume will land in a different volume bucket than the average monthly search.
- Fresh: Keyword Planner updates once a month, with averages not providing predictive value. A hot new keyword will look 1/12th its actual volume in the average monthly search, and it won't show up for 30 days.
- Relatable: You can group keywords in 1 of the 84 different volume buckets, with no explanation as to how the groups were formed. (They appear to be associated with a simple logarithmic curve.)
You can see why we were concerned. The numbers aren't that specific, have ranges that are literally wrong most of the time, are updated regularly but infrequently, and aren't very group-able. Well, we had our work cut out for us, so we began in earnest attacking the problems...
Balancing specificity and coverage
As you can imagine, there's a direct trade-off between specificity and coverage. The tighter the volume ranges, the higher the specificity and lower the coverage. The broader the ranges, the lower the specificity and higher coverage. If we only had one range that was from zero to a billion, we would have horrible specificity and perfect coverage. If we had millions of ranges, we would have perfect specificity but no coverage. Given our weightings and parameters, we identified the best possible arrangement. I'm pretty sure there's a mathematical expression of this problem that would have done a quicker job here, but I am not a clever man, so I used my favorite tool of all: brute force. The idea was simple.
- We take the maximum and minimum boundaries of the search volume data provided by Google Keyword Planner, lets say... between 0 and 1 billion.
- We then randomly divide it into ranges — testing a reasonable number of ranges (somewhere between 10 and 25). Imagine randomly placing dividers between books on a shelf. We did that, except the books were keyword volume numbers.
- We assign a weighting to the importance of specificity (the distance between the average of the range min and max from the keyword's actual average monthly search). For example, we might say that it's 80% important that we're close to the average for the year.
- We assign a weighting to the importance of coverage (the likelihood that any given month over the last year falls within the range). For example, we might say it's 20% important that we're close to the average each month.
- We test 100,000 randomly selected keywords and their Google Keyword Planner volume against the randomly selected ranges.
- We use the actual average of the last 12 months rather than the rounded average of the last 12 months.
- We do this for millions of randomly selected ranges.
- We select the winner from among the top performers.
It took a few days to run (the longer we ran it, the rarer new winners were discovered). Ultimately, we settled on 20 different ranges (a nice, whole number for grouping and displaying purposes) that more than doubled the coverage rate over the preexisting Google Keyword Planner data while minimizing damage to specificity as much as possible. Let me give an example of how this could be useful. Let's take the keyword "baseball." It's fairly seasonal, although it has a long season.

In the above example, the Google Average Monthly Search for Baseball is 368,000. The range this covers is between around 330K and 410K. As you can see, this range only covers 3 of the 12 months. The Moz range covers 10 of the 12 months.
Now, imagine that you're a retailer that's planning PPC and SEO marketing for the next year. You make your predictions based on the 368,000 number given to you by Google Keyword Planner. You'll actually under-perform the average 8 months out of the year. That's a hard pill to swallow. But, with the Moz range, you can use the lower boundary as a "worst-case scenario." With the Moz range, your traffic under-performs only 2 months out of the year. Why pretend that we can get the exact average when we know the exact average is nearly always wrong?
Improving relatability
This followed naturally from our balancing specificity and coverage. We did end up choosing 20 groupings over some higher-performing groupings that were less clean numbers (like 21 groupings) for aesthetic and usability purposes. But what this means is that it's easy to group keywords by volume and not in an arbitrary fashion. You could always group by ranges in Excel, if you wanted, but the ranges you came up with off the top of your head wouldn't have been validated in any way regarding the underlying data.
Let me give an example why this matters. Intuitively, you'd imagine that the ranges would increase in broadness in a similar logarithmic fashion as they get larger. For example, you might think most keywords are 10% volatile, so if a keyword is searched 100 times a month, you might expect some months to be 90 and others 110. Similarly, you would expect a keyword searched 1,000 times a month to vary 10% up or down as well. Thus, you would create ranges like 0–10, 100–200, 1,000–2,000, etc. In fact, this appears to be exactly what Google does. It's simple and elegant. But is it correct?
Nope. It turns out that keyword data is not congruent. It generally follows these patterns, but not always. For example, in our analysis, we found that while the volume range after 101–200 is 201–500 (a 3x increase in broadness), the very next optimal range is actually 501–850, only a 1/6th increase in broadness.
This is likely due to non-random human search patterns related to certain keywords. There are keywords which people probably search daily, weekly, monthly, quarterly, etc. Imagine keywords like "what is the first Monday of this month" and "what is the last Tuesday of this month." All of these keywords would be searched a similar number of times by a similar population a similar number of times each month, creating a congruency that is non-random. These patterns create shifts in the volatility of terms that are not congruent with a natural logarithmic scale you would expect if the data was truly random. Our machine-learned volume ranges capture this non-random human behavior efficiently and effectively.
We can actually demonstrate this quite easily in a graph.

Notice in this graph that the log of Google's Keyword Planner volume ranges are nearly linear, except at the tail ends. This would indicate that Google has done very little to try and address patterns in search behavior that make the data non-random. Instead, they apply a simple logarithmic curve to their volume buckets and leave it at that. The R2 value shows just how close to 1 (perfect linearity) this relationship is.

The log of Moz's keyword volume ranges are far less linear, which indicates that our range-optimization methodologies found anomalies in the search data which do not conform to a perfect logarithmic relationship with search volume volatility. These anomalies are most likely caused by real non-random patterns in human search behavior. Look at positions 11 and 12 in the Moz graph. Our ranges actually contract in breadth at position 12 and then jump back up at 13. There is a real, data-determined anomaly which shows the searches in that range actually have less volatility than the searches in the previous range, despite being searched more often.
Improving freshness
Finally, we improved freshness by using a completely new, thirrd-party anonymized clickstream data set. Yes, we analyze 1-hour delayed clickstream data to capture new keywords worth including both in our volume data and our corpus. Of course, this was a whole feat in and of itself; we have to parse and clean hundreds of millions of events daily into usable data. Furthermore, a lot of statistically significant shifts in search volume are actually ephemeral. Google Doodles are notorious for this, causing huge surges in traffic for obscure keywords just for a single day. We subsequently built models to look for keywords that trended upward over a series of days, beyond the expected value. We then used predictive models to map that clickstream search volume to a bottom quartile range (i.e.: we were intentionally conservative in our estimates until we could validate against next month's Google Keyword Planner data).
Finally, we had to remove inherent biases from the clickstream dataset itself so that we were confident our fresh data was reliable. We accomplished this by...
- Creating a naive model that predicts Google Keyword Volume from the clickstream data
- Tokenizing the clickstream keywords and discovering words and phrases that correlate with outliers
- Building a depressing and enhancing map of these tokens to modify the predictive model based on their inclusion
- Applied the map to the naive model to give us better predictions.
This was a very successful endeavor in that we can take raw clickstream data and, given certain preconditions (4 weeks of steady data), we can predict with 95% accuracy the appropriate volume range.
A single metric
All of this above — the research into why Google Keyword Planner is inadequate, the machine-learned ranges, the daily freshness volume updating, etc. — all goes into a single, seemingly simple, metric: Volume Ranges. This is probably the least-scrutinized of our metrics because it's the most straightforward. Keyword Difficulty, Organic CTR, and Keyword Priority went through far more revisions and are far more sophisticated in their approach, analysis, and production.
But we aren't done. We're actively looking at improving the volume metric by adding more and better data sources, predicting future traffic, and potentially providing a mean along with the ranges. We appreciate any feedback you might offer, as well, on what the use cases might be for different styles of volume metrics
However, at the end of the day, I hope what you come away with is this: At Moz, we sweat the details so you don't have to.
A personal note
This is my first big launch at Moz. While I dearly miss my friends and colleagues at Angular (the consulting firm for whom I worked for the past 10 years), I can't say enough about the amazing people I work with here. Most of them will never blog here, won't tweet, and won't speak at conferences. But they deserve all the credit. So, here's a picture of my view from Google Hangouts from a Keyword Explorer meeting. Most of the team was able to make it, but those who didn't, you know who you are. Thanks for sweating the details.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.